
はじめに
データ分析において、集計や統計解析は非常に重要な役割を持っています。Pandasは、Pythonでデータ処理を行うためのライブラリであり、その中でも特にgroupby機能はデータ集計において強力なツールとして知られています。groupbyを用いることで、カテゴリごとにデータをまとめたり、異なる集計方法でデータを集計したりすることができます。
groupbyの基本概念と利点
groupbyは、データフレームをグループに分け、各グループに対して集計処理を行う機能です。groupbyを用いることで、以下のようなことが可能になります。
- カテゴリごとにデータをまとめる
- グループごとに集計処理を行う
- 集計結果を新しいデータフレームとして出力する
このような機能を利用することで、膨大なデータを効率的に処理し、データから新たな知見を見出すことが可能になります。
pandasでのgroupbyの使い方と実行方法
groupbyを用いるには、PandasのDataFrameオブジェクトに対して、groupbyメソッドを実行します。groupbyメソッドは、まずグループキーを指定し、次に集計方法を指定する必要があります。
グループキーの指定方法
グループキーは、分類するためのカラム名、配列、シリーズ、または、グループごとに分類するための関数を指定することができます。
カラム名を指定する場合
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの平均値を算出しています。
import pandas as pd
df = pd.DataFrame({'category':
['A', 'A', 'B', 'B', 'B'], 'value': [1, 2, 3, 4, 5]})
grouped = df.groupby('category')
result = grouped.mean()
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
value category A 1.5 B 4.0
配列やシリーズを指定する場合
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの平均値を算出しています。ここでは、グループキーとしてcategoryカラムの値の配列を指定しています。
import pandas as pd
df = pd.DataFrame({'category': ['A', 'A', 'B', 'B', 'B'], 'value': [1, 2, 3, 4, 5]})
grouped = df.groupby(df['category'])
result = grouped.mean()
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
value category A 1.5 B 4.0
関数を指定する場合
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの平均値を算出しています。ここでは、グループキーとしてcategoryカラムの値を大文字に変換した結果を返す関数を指定しています。
import pandas as pd
df = pd.DataFrame({'category': ['A', 'a', 'B', 'b', 'B'], 'value': [1, 2, 3, 4, 5]})
def get_upper(x):
return x.str.upper()
grouped = df.groupby(get_upper(df['category']))
result = grouped.mean()
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
value category A 1.5 B 4.0
集計方法の指定方法
groupbyメソッドを使用してグループ化した後、いくつかの統計的な集計関数を使用して集計を行うことができます。例えば、平均値、最大値、最小値、中央値、合計値などがあります。
統計関数の一覧
- mean():平均値を計算
- sum():合計値を計算
- min():最小値を計算
- max():最大値を計算
- count():各グループの要素数を計算
- std():標準偏差を計算
- var():分散を計算
- describe():平均、標準偏差、最小値、最大値、四分位数などの統計情報を計算
集計関数の例
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの合計値、最大値、最小値を算出しています。
import pandas as pd
df = pd.DataFrame({'category': ['A', 'A', 'B', 'B', 'B'], 'value': [1, 2, 3, 4, 5]})
grouped = df.groupby('category')
result = grouped.agg({'value': ['sum', 'max', 'min']})
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
value
sum max min
category
A 3 2 1
B 12 5 3
集約関数とカスタム集計の活用
集約関数を使うことで、groupbyでグループ化したデータに対して、より高度な集計処理を行うことができます。また、カスタム集計関数を定義することで、独自の集計方法を定義することができます。
集約関数の使用方法
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの最大値と最小値の差を算出しています。
import pandas as pd
df = pd.DataFrame({'category': ['A', 'A', 'B', 'B', 'B'], 'value': [1, 2, 3, 4, 5]})
grouped = df.groupby('category')
result = grouped['value'].agg(lambda x: max(x) - min(x))
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
category A 1 B 2 Name: value, dtype: int64
<h3カスタム集計の使用方法< h3=””>
以下の例では、データフレームを「category」と「value」の2つのカラムで定義し、categoryごとにグループ化して、それぞれのグループ内のvalueの95%信頼区間を算出しています。ここでは、カスタム集計関数として「calc_confidence_interval」という関数を定義しています。
import pandas as pd
import numpy as np
from scipy.stats import t
df = pd.DataFrame({'category': ['A', 'A', 'B', 'B', 'B'], 'value': [1, 2, 3, 4, 5]})
def calc_confidence_interval(x):
n = len(x)
mean = np.mean(x)
std = np.std(x, ddof=1)
stderr = std / np.sqrt(n)
interval = t.interval(0.95, n-1)
return stderr * interval[1]
grouped = df.groupby('category')
result = grouped['value'].agg(calc_confidence_interval)
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
category A 6.353102 B 2.484138 Name: value, dtype: float64
groupbyを用いたデータ解析の実践的応用例
groupbyは、データ分析において非常に有用なツールであり、多くの応用例があります。ここでは、以下のような実践的な応用例を紹介します。
カテゴリごとの統計量の算出
データフレームをカテゴリごとにグループ化して、各カテゴリの統計量を算出することができます。例えば、以下の例では、irisデータセットを種別ごとにグループ化し、各グループの平均値、標準偏差、中央値を算出しています。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target_names[iris.target]
grouped = df.groupby('target')
result = grouped.describe()
print(result)
上記のコードを実行すると、以下のような出力結果が得られます。
sepal length (cm) ... petal width (cm)
count mean std min ... 25% 50% 75% max
target ...
setosa 50.0 5.006 0.352490 4.3 ... 0.2 0.2 0.3 0.6
versicolor 50.0 5.936 0.516171 4.9 ... 1.2 1.3 1.5 1.8
virginica 50.0 6.588 0.635880 4.9 ... 1.8 2.0 2.3 2.5
[3 rows x 32 columns]
データフレームをカテゴリごとにグループ化し、各グループのデータをグラフに表示することができます。例えば、以下の例では、seabornライブラリを使用して、irisデータセットを種別ごとにグループ化し、各グループのpetal lengthとpetal widthの散布図を作成しています。
import pandas as pd import seaborn as sns from sklearn.datasets import load_iris import matplotlib.pyplot as plt iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target_names[iris.target] sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='target', data=df) # グラフの表示 plt.show()
上記のコードを実行すると、以下のようなグラフが表示されます。
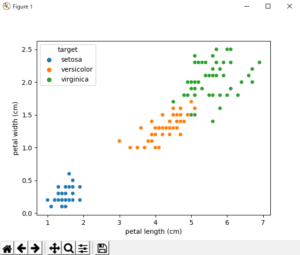
グループ間の比較
データフレームをグループ化し、グループ間の比較を行うことができます。例えば、以下の例では、seabornライブラリを使用して、irisデータセットを種別ごとにグループ化し、各グループのpetal lengthのヒストグラムを作成しています。
import pandas as pd import seaborn as sns from sklearn.datasets import load_iris import matplotlib.pyplot as plt iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target_names[iris.target] sns.histplot(x='petal length (cm)', hue='target', data=df, element='step') # グラフの表示 plt.show()
上記のコードを実行すると、以下のようなグラフが表示されます。
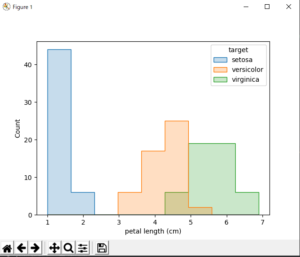
まとめ
groupbyメソッドは、pandasを使用したデータ処理において非常に有用なツールであり、データフレームをグループ化して各グループの統計量を算出したり、グループ間の比較を行ったりすることができます。また、集約関数やカスタム集計関数を使用することで、より高度な集計処理を行うことができます。groupbyメソッドを使いこなすことで、より効率的なデータ処理が可能となります。


![[Python]スクレイピング !表形式(csv,テーブル)へのデータ抽出](https://machine-learning-skill-up.com/knowledge/wp-content/uploads/2023/12/1-1362.jpg)


