
はじめに
この記事では、Pythonのデータ分析ライブラリPandasを使って、列指定で正規化を行う方法について解説します。
正規化とは何か、その重要性について
正規化は、データをある特定の範囲に収めることで、比較や解析がしやすくなるようにする処理のことです。正規化を行うことで、データのばらつきを抑え、外れ値の影響を受けにくくなります。また、正規化を行うことで、機械学習のようなデータ分析の精度を高めることができます。
Pandasでデータフレームを読み込む方法
Pandasは、Pythonでデータ分析を行う際によく使われるライブラリです。まずは、Pandasを用いてデータフレームを読み込む方法について説明します。
例えば、以下のようなCSVファイルを読み込む場合、Pandasのread_csv()関数を使います。
import pandas as pd
df = pd.read_csv('data.csv')
print(df.head())
このコードでは、data.csvファイルを読み込んで、その中身をデータフレームとして変数dfに格納しています。データフレームの先頭5行を表示するには、head()メソッドを使います。
列指定で正規化を行う方法
次に、Pandasを使って列指定で正規化を行う方法について説明します。Pandasでは、データフレームの各列に対して、min-maxスケーリングやz-scoreスケーリングといった正規化を行うことができます。
min-maxスケーリング
min-maxスケーリングは、データを最小値と最大値の範囲内に収める処理です。この処理によって、データの最小値が0、最大値が1になるように変換されます。以下のコードは、データフレームのage列をmin-maxスケーリングする例です。
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df['age_normalized'] = scaler.fit_transform(df[['age']]) print(df.head())
このコードでは、sklearn.preprocessingモジュールからMinMaxScalerクラスをインポートして、変数scalerにインスタンスを作成しています。そして、fit_transform()メソッドを使って、age列をmin-maxスケーリングし、新しい列age_normalizedとして追加しています。
z-scoreスケーリング
z-scoreスケーリングは、データの平均値を0、標準偏差を1に変換する処理です。この処理によって、データの平均値が0、標準偏差が1になるように変換されます。以下のコードは、データフレームのage列をz-scoreスケーリングする例です。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df['age_normalized'] = scaler.fit_transform(df[['age']]) print(df.head())
このコードでは、sklearn.preprocessingモジュールからStandardScalerクラスをインポートして、変数scalerにインスタンスを作成しています。そして、fit_transform()メソッドを使って、age列をz-scoreスケーリングし、新しい列age_normalizedとして追加しています。
正規化の種類と選び方
正規化には、min-maxスケーリングやz-scoreスケーリング以外にも、さまざまな種類があります。正規化の種類を選ぶ際には、データの性質や目的に合わせて適切なものを選ぶ必要があります。
min-maxスケーリングは、データの範囲を[0, 1]に収めることができるため、画像処理などでよく使われます。一方、z-scoreスケーリングは、データの分布が正規分布に近い場合に有効です。また、正規化を行う前に、データの分布や外れ値を確認することも重要です。
実践的な例を通しての正規化の適
ここでは、実践的な例を通して正規化の適用方法を解説します。以下の例では、UCI Machine Learning Repositoryから取得したWine Qualityデータセットを使用します。
まずは、必要なライブラリをインポートして、データを読み込みます。
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv' df = pd.read_csv(url, sep=';') print(df.head())
次に、データの分布を確認してみましょう。以下のコードは、ヒストグラムを描画する例です。
sns.histplot(data=df, x='alcohol', kde=True) plt.show()
このコードでは、Seabornライブラリを使って、データフレームのalcohol列のヒストグラムを描画しています。以下のようなグラフが表示されます。
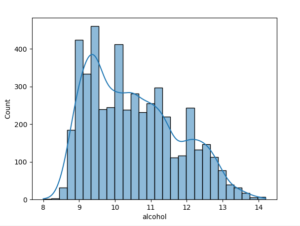
このヒストグラムからは、alcoholの分布が右に偏っていることがわかります。このままでは、正規化を行うことができないため、まずは外れ値を除外してみましょう。
q1 = df['alcohol'].quantile(0.25) q3 = df['alcohol'].quantile(0.75) iqr = q3 - q1 df = df[(df['alcohol'] > (q1 - 1.5 * iqr)) & (df['alcohol'] < (q3 + 1.5 * iqr))]
このコードでは、alcohol列の四分位範囲を計算して、外れ値を除外しています。
次に、min-maxスケーリングを行ってみましょう。
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df['alcohol_normalized'] = scaler.fit_transform(df[['alcohol']]) print(df.head())
このコードでは、MinMaxScalerを使って、alcohol列をmin-maxスケーリングして、新しい列alcohol_normalizedとして追加しています。
最後に、正規化前と正規化後の分布を比較してみましょう。
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
sns.histplot(data=df, x='alcohol', kde=True, ax=ax[0])
sns.histplot(data=df, x='alcohol_normalized', kde=True, ax=ax[1])
ax[0].set_title('Before normalization')
ax[1].set_title('After normalization')
plt.show()
このコードでは、Seabornライブラリを使って、正規化前と正規化後のヒストグラムを比較しています。以下のようなグラフが表示されます。
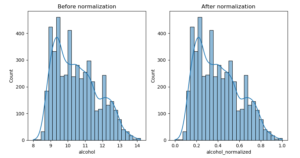
このグラフからは、正規化によって分布が[0, 1]の範囲に収まったことがわかります。
まとめ
この記事では、Pythonのデータ分析ライブラリPandasを使って、列指定で正規化を行う方法について解説しました。また、正規化の種類や選び方についても説明しました。正規化は、データ分析の精度を高めるために欠かせない前処理の一つです。ぜひ、今後のデータ分析に役立ててください。





