
はじめに
この記事ではscikit-learnを使って、機械学習の入門用のデータとしてよく使われる糖尿病データから線形回帰モデルを構築する方法を紹介します。
糖尿病データセットの概要とscikit-learnの利用方法
糖尿病データセットは、糖尿病患者の血液中の特定のバイオマーカーの測定値と、1年後の疾患進行の測定値を含む、総数442件の観測値からなります。
scikit-learnは、Pythonの機械学習ライブラリで、機械学習アルゴリズムを簡単に実装できます。scikit-learnには、糖尿病データセットを含む多くのデータセットが用意されています。データセットを読み込むには、以下のようにします。
from sklearn.datasets import load_diabetes diabetes = load_diabetes() X, y = diabetes.data, diabetes.target
このコードでは、load_diabetes()関数を使って糖尿病データセットを読み込み、説明変数をX、目的変数をyに格納しています。
データの前処理と特徴量選択
データの前処理として、欠損値の処理やスケーリングが必要です。欠損値が含まれている場合は、scikit-learnのImputerクラスを使って補完することができます。
import numpy as np from sklearn.impute import SimpleImputer imputer = SimpleImputer(missing_values=np.nan, strategy='mean') imputer.fit(X)
スケーリングは、説明変数の範囲を揃えるために行われます。線形回帰モデルでは、説明変数の範囲が大きく異なる場合、モデルの係数が不安定になる可能性があります。scikit-learnのStandardScalerクラスを使って、説明変数をスケーリングすることができます。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
特徴量選択は、説明変数の数を減らし、モデルの複雑さを抑えるために行われます。ここでは、Lasso回帰を使って、係数が0に近い説明変数を削除します。
from sklearn.linear_model import Lasso lasso = Lasso(alpha=0.1) lasso.fit(X_scaled, y) X_selected = X_scaled[:, lasso.coef_ != 0]
このコードでは、Lasso回帰のalphaパラメータを0.1に設定し、fit()メソッドを使ってモデルを学習します。そして、coef_属性を使って、係数が0でない説明変数を選択します。
線形回帰モデルの構築と学習
線形回帰モデルは、説明変数と目的変数の間の線形関係をモデル化します。scikit-learnのLinearRegressionクラスを使って、線形回帰モデルを構築することができます。
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_selected, y)
このコードでは、LinearRegressionクラスを使って線形回帰モデルを構築し、fit()メソッドを使ってモデルを学習します。
モデルの評価指標と予測結果の解釈
モデルの評価指標として、平均二乗誤差(Mean Squared Error, MSE)と決定係数(Coefficient of Determination, R^2)を使います。
from sklearn.metrics import mean_squared_error, r2_score y_pred = model.predict(X_selected) mse = mean_squared_error(y, y_pred) r2 = r2_score(y, y_pred)
このコードでは、predict()メソッドを使って、モデルから予測値を求めます。そして、mean_squared_error()関数とr2_score()関数を使って、MSEとR^2を計算します。
線形回帰モデルの係数と切片は、以下のようにして取得できます。
coefficients = model.coef_ intercept = model.intercept_
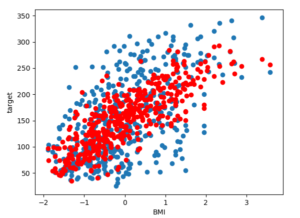
これらの係数を使って、説明変数と目的変数の間の線形関係を解釈することができます。例えば、以下のようなコードを使って、BMIと目的変数の関係を可視化することができます。
import matplotlib.pyplot as plt
plt.scatter(X_selected[:, 2], y)
plt.scatter(X_selected[:, 2], model.predict(X_selected), color='red')
plt.xlabel('BMI')
plt.ylabel('target')
plt.show()
このコードでは、scatter()関数を使って、BMIと目的変数の散布図を描画し、線形回帰モデルの予測値を散布図で描画しています。
まとめ
糖尿病データセットを使って、線形回帰モデルを構築する方法を紹介しました。データの前処理や特徴量選択、モデルの学習、評価指標の計算、予測結果の解釈など、機械学習の基本的な手順を実践することができました。
scikit-learnは、Pythonの機械学習ライブラリとして非常に有用であり、簡単に機械学習アルゴリズムを実装できます。今後も、scikit-learnを使って、様々な機械学習の問題に取り組んでいきましょう。




![[Python]図形検出と面積計算 画像解析の基本スキルを身につける](https://machine-learning-skill-up.com/knowledge/wp-content/uploads/2023/12/1-1376.jpg)
