![Pandasを使ったヒストグラムの描画法[Python]](https://machine-learning-skill-up.com/knowledge/wp-content/uploads/2023/10/1-48.jpg)
はじめに
本記事では、Pythonのデータ解析ライブラリであるPandasを使用して、ヒストグラムの描画方法について解説します。ヒストグラムはデータの分布を可視化するための有用なグラフです。Pandasはデータの読み込みや前処理、データ解析の機能を提供しており、ヒストグラムの描画も簡単に行うことができます。
Pandasとヒストグラムについての基本的な説明
まず、Pandasについて簡単に説明しましょう。PandasはPythonでよく使われるデータ解析ライブラリであり、テーブル形式のデータを操作するための便利な機能を提供しています。Pandasでは、データをデータフレームと呼ばれる表の形式で扱います。
ヒストグラムは、データの分布を視覚的に把握するためのグラフです。データを特定の範囲に区切り、それぞれの範囲内に含まれるデータの数をカウントします。そして、各範囲のカウント数を縦軸にプロットすることで、データの分布を表現します。
Pandasを用いたヒストグラムの基本的な描画方法
まずはじめに、Pandasを使ってヒストグラムを描画する基本的な方法について説明します。以下のコードは、Pandasのデータフレームからヒストグラムを描画する例です。
import pandas as pd
import matplotlib.pyplot as plt
# データフレームの作成
data = pd.DataFrame({'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5]})
# ヒストグラムの描画
plt.hist(data['A'])
# グラフのタイトルと軸ラベルの設定
plt.title('Histogram of A')
plt.xlabel('Value')
plt.ylabel('Frequency')
# グラフの表示
plt.show()
上記のコードでは、Pandasのデータフレームを作成し、その列’A’のデータをヒストグラムとして描画しています。Matplotlibを使用してグラフを作成し、タイトルや軸ラベルを設定し、最後にグラフを表示しています。
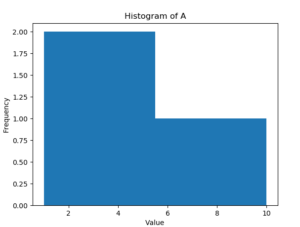
このように、Pandasを使用することで、データフレームから簡単にヒストグラムを描画することができます。
ヒストグラムのビン数や範囲などの設定方法
ヒストグラムの描画時には、ビン数や範囲などの設定が重要です。ビン数はデータをいくつの区間に分割するかを指定し、範囲はデータの最小値と最大値の範囲を指定します。
Pandasのヒストグラム描画メソッドである`hist()`には、ビン数や範囲を指定するためのパラメータがあります。以下のコードは、ビン数を10、範囲を0から10に設定してヒストグラムを描画する例です。
# ヒストグラムの描画(ビン数=10、範囲=0から10) plt.hist(data['A'], bins=10, range=(0, 10))
ビン数や範囲の設定は、データの性質や可視化したい情報に応じて適切に調整する必要があります。試行錯誤しながら最適な設定を見つけることが重要です。
複数のデータセットに対するヒストグラムの並列描画や重ね描画方法
複数のデータセットに対してヒストグラムを描画する場合、並列描画や重ね描画を利用することで比較や相関を視覚的に把握することができます。
以下のコードは、複数のデータセットに対してヒストグラムを並列描画する例です。
# データフレームの作成
data = pd.DataFrame({'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'B': [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]})
# ヒストグラムの並列描画
plt.hist(data[['A', 'B']], bins=10, alpha=0.5, label=['A', 'B'])
# グラフのタイトルと軸ラベルの設定
plt.title('Histogram of A and B')
plt.xlabel('Value')
plt.ylabel('Frequency')
# 凡例の表示
plt.legend()
# グラフの表示
plt.show()
上記のコードでは、データフレームに列’A’と列’B’のデータが含まれており、それぞれのヒストグラムを並列描画しています。`alpha`パラメータを使用することで、ヒストグラムの透明度を調整し、重なり具合を調整しています。
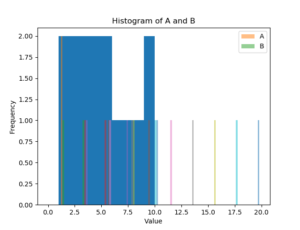
また、複数のヒストグラムを重ねて描画する場合は、`hist()`メソッドを複数回呼び出すことで実現できます。以下のコードは、列’A’と列’B’のヒストグラムを重ねて描画する例です。
# ヒストグラムの重ね描画
plt.hist(data['A'], bins=10, alpha=0.5, label='A')
plt.hist(data['B'], bins=10, alpha=0.5, label='B')
# グラフのタイトルと軸ラベルの設定
plt.title('Histogram of A and B')
plt.xlabel('Value')
plt.ylabel('Frequency')
# 凡例の表示
plt.legend()
# グラフの表示
plt.show()
重ね描画では、各ヒストグラムに対して異なるラベルを指定することで、凡例に表示されるようにしています。
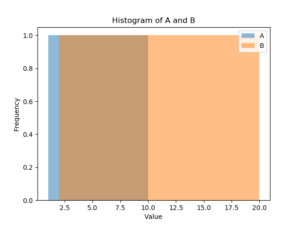
ヒストグラムから得られる情報とその解釈の仕方
ヒストグラムからは、データの分布や特徴を把握することができます。ヒストグラムから得られる主な情報とその解釈方法を以下に示します。
- ピーク(最頻値): ヒストグラムで最も頻度が高い範囲や値を示しており、データの中心傾向を表しています。
- 分布の形状: ヒストグラムの形状から、データが対称的であるか、左右に偏りがあるか、または複数のピークを持つかなどを判断することができます。
- 範囲: ヒストグラムの横軸の範囲から、データの最小値と最大値を把握することができます。
- 外れ値: ヒストグラムの範囲外に存在する値は、データの外れ値を表しています。
これらの情報を解釈することで、データの傾向や特徴を把握し、適切なデータ分析や意思決断を行うことができます。例えば、ピークが1つのヒストグラムではデータが一様に分布している可能性が高く、左右に偏った形状のヒストグラムではデータが偏っていることが示唆されます。また、ヒストグラムを活用したデータ分析の具体的な事例として、以下のようなケースがあります。データの分布の比較: 異なるグループや条件下でのデータの分布を比較することで、グループ間の差異やパターンを把握することができます。
例えば、AグループとBグループのヒストグラムを比較し、2つのグループのデータがどのように異なるのかを可視化できます。外れ値の検出: ヒストグラムにおいて、範囲外の値や非常に低頻度の値が存在する場合、これらはデータセットの外れ値を示している可能性があります。ヒストグラムを確認することで、外れ値を特定し、必要に応じて除外するなどの処理を行うことができます。データの分布の形状の判断: ヒストグラムの形状から、データが正規分布に従っているか、左右に偏った分布であるか、または複数のピークを持つ分布であるかを判断することができます。これにより、データの特性を把握し、適切な統計解析手法やモデルの選択に役立てることができます。
まとめ
本記事では、PythonのPandasライブラリを使用してヒストグラムを描画する方法について解説しました。Pandasを利用することで、簡単にデータフレームからヒストグラムを作成することができます。また、ビン数や範囲の設定、複数のデータセットの比較や重ね描画、ヒストグラムから得られる情報の解釈など、より高度なヒストグラムの活用方法についても紹介しました。


![[Python]文字列を日時に変換する方法 日付と時間の操作](https://machine-learning-skill-up.com/knowledge/wp-content/uploads/2023/12/1-1386.jpg)


