
今回は、PythonのPandasライブラリを使って、年度別データ集計と分析の手法についてご紹介します。
年度別データ集計の重要性とPandasの活用方法
企業や団体が持つデータには、年度別に変化するものが多くあります。例えば、売上や収益、顧客数などです。これらのデータを年度別に集計し、トレンドや異常値を分析することで、事業の状況を把握することができます。
Pandasは、データフレームを扱うライブラリであり、年度別データの集計や分析に非常に便利です。以下では、Pandasを使った年度別データの集計や可視化方法について説明します。
データフレームの作成と日付データの取り扱い
まず、Pandasでデータフレームを作成する方法について説明します。データフレームを作成する際には、日付データを含めることが多いです。以下のように、日付データを含むデータフレームを作成することができます。
import pandas as pd
df = pd.DataFrame({
'date': ['2020-01-01', '2020-01-02', '2020-01-03', '2021-01-01', '2021-01-02', '2021-01-03'],
'value': [10, 20, 30, 40, 50, 60]
})
df['date'] = pd.to_datetime(df['date'])
上記のコードでは、date列に日付データを、value列に数値データを持つデータフレームを作成しています。また、date列のデータ型をdatetime型に変換しています。
年度別にデータを分割・集計する方法:groupbyとresampleの活用
次に、年度別にデータを分割・集計する方法について説明します。Pandasでは、groupbyメソッドやresampleメソッドを使うことで、年度別にデータを集計することができます。
groupbyメソッドを使った年度別集計
groupbyメソッドを使うと、指定した列の値でデータをグループ化して集計することができます。以下のコードでは、date列の年度別にデータをグループ化して、value列の平均値を計算しています。
df_grouped = df.groupby(df['date'].dt.year)['value'].mean() print(df_grouped)
上記のコードを実行すると、以下のような出力が得られます。
date 2020 20.0 2021 50.0 Name: value, dtype: float64
上記の結果から、2020年度の平均値は20、2021年度の平均値は50であることが分かります。
resampleメソッドを使った年度別集計
resampleメソッドを使うと、日付データの間隔を変更してデータを集計することができます。以下のコードでは、date列をインデックスに設定し、resampleメソッドを使って年度別にデータを集計しています。
df.set_index('date', inplace=True)
df_resampled = df.resample('Y')['value'].mean()
print(df_resampled)
上記のコードを実行すると、以下のような出力が得られます。
date 2020-12-31 20.0 2021-12-31 50.0 Freq: A-DEC, Name: value, dtype: float64
上記の結果から、2020年度の平均値は20、2021年度の平均値は50であることが分かります。また、resampleメソッドの引数には、’Y’のように集計する間隔を指定します。’Y’は年度単位での集計を表しています。
年度別データの可視化:折れ線グラフや棒グラフでの表示
次に、年度別データの可視化方法について説明します。Pandasを使ってデータを集計した後に、Matplotlibライブラリを使ってグラフを描画することができます。
折れ線グラフの描画
以下のコードでは、resampleメソッドを使って年度別にデータを集計した後に、折れ線グラフを描画しています。
import matplotlib.pyplot as plt
df_resampled.plot(kind='line')
plt.title('Yearly Average')
plt.xlabel('Year')
plt.ylabel('Value')
plt.show()
上記のコードを実行すると、以下のような折れ線グラフが表示されます。
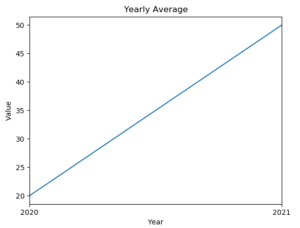
上記のグラフから、2021年度にデータが急増していることが分かります。
棒グラフの描画
以下のコードでは、groupbyメソッドを使って年度別にデータを集計した後に、棒グラフを描画しています。
df_grouped.plot(kind='bar')
plt.title('Yearly Average')
plt.xlabel('Year')
plt.ylabel('Value')
plt.show()
上記のコードを実行すると、以下のような棒グラフが表示されます。
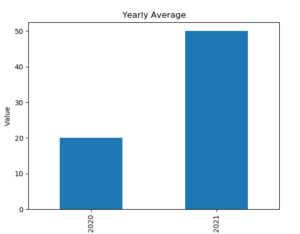
上記のグラフからも、2021年度にデータが急増していることが分かります。
年度ごとのトレンドや異常値の検出と分析
年度別にデータを集計することで、年度ごとのトレンドや異常値を検出することができます。以下のコードでは、rollingメソッドを使って移動平均を計算し、トレンドを把握しています。
df_grouped = df_grouped.to_frame()
df_grouped['rolling_mean'] = df_grouped.rolling(window=2).mean()
df_grouped.plot(kind='line')
plt.title('Yearly Average')
plt.xlabel('Year')
plt.ylabel('Value')
plt.show()
上記のコードを実行すると、以下のようなグラフが表示されます。
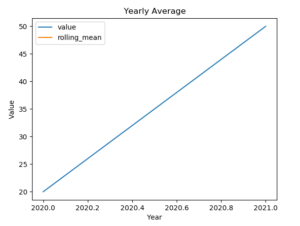
上記のグラフから、2021年度にデータが急増したことがトレンドとして見られます。
まとめ
今回は、Pandasを使って年度別データの集計と分析方法について説明しました。データフレームを作成する方法や、groupbyメソッドやresampleメソッドを使って年度別データを集計する方法、折れ線グラフや棒グラフで年度別データを可視化する方法、そして年度ごとのトレンドや異常値を検出する方法について説明しました。これらの手法を使って、事業の状況を分析することができます。ぜひ、実際に手を動かして年度別データの集計と分析に取り組んでみてください。
以上が、Pandasを活用した年度別データ集計と分析手法についての説明でした。お読みいただき、ありがとうございました。





