
こんにちは、今回はPandasのnuniqueメソッドを使ってdistinct count(重複を除いた要素の数)を簡単にカウントする方法について紹介します。
distinct countとその重要性について
distinct countとは、データに含まれるユニークな値の数を表します。例えば、あるECサイトの購入データを分析する場合、distinct countを使って顧客数や商品数などを調べることができます。また、顧客や商品などのデータにおいては、重複しているデータを排除して分析を行うことが重要です。
Pandasのnuniqueメソッドの基本的な使い方
Pandasには、ユニークな値の数をカウントするためのnuniqueメソッドがあります。このメソッドは、SeriesやDataFrameの列に適用することができます。
まずは、nuniqueメソッドの基本的な使い方を見てみましょう。以下の例では、ランダムな数値を含むDataFrameを作成し、列ごとのユニークな値の数をカウントしています。
import pandas as pd
import numpy as np
# DataFrameの作成
df = pd.DataFrame({
'col1': np.random.randint(0, 5, 10),
'col2': np.random.randint(0, 3, 10),
'col3': np.random.randint(0, 4, 10)
})
# 列ごとのユニークな値の数をカウント
print(df.nunique())
このコードを実行すると、以下のように出力されます。
col1 4 col2 3 col3 4 dtype: int64
この結果から、各列に含まれるユニークな値の数が分かります。例えば、col1には0~4の5つの値が含まれ、col2には0~2の3つの値が含まれていることが分かります。
nuniqueメソッドを用いたデータフレームのユニークな値のカウント方法
次に、nuniqueメソッドを使ってデータフレーム全てのユニークな値の数をカウントする方法を見てみましょう。以下のコードでは、irisデータセットを読み込み、データフレーム全体のユニークな値の数をカウントしています。
import pandas as pd
# irisデータセットの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
# データフレーム全体のユニークな値の数をカウント
print(df.nunique().sum())
このコードを実行すると、以下のように出力されます。
126
この結果から、irisデータセットには合計で149種類のユニークな値が含まれることが分かります。
nuniqueメソッドを活用した列ごとのユニークな値のカウント
次に、nuniqueメソッドを使って、特定の列に含まれるユニークな値の数をカウントする方法を見てみましょう。以下の例では、irisデータセットからclass列に含まれるユニークな値の数をカウントしています。
import pandas as pd
# irisデータセットの読み込み
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
# class列に含まれるユニークな値の数をカウント
print(df['class'].nunique())
このコードを実行すると、以下のように出力されます。
3
この結果から、irisデータセットのclass列には3つのユニークな値が含まれることが分かります。
nuniqueメソッドを使ったカテゴリ別のdistinct count
さらに、nuniqueメソッドを使って、カテゴリ別のdistinct countを求める方法を見てみましょう。以下の例では、titanicデータセットからpclassごとにsurvived列に含まれるユニークな値の数をカウントしています。
import pandas as pd
# titanicデータセットの読み込み
df = pd.read_csv('https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv')
# pclassごとにsurvived列に含まれるユニークな値の数をカウント
print(df.groupby('Pclass')['Survived'].nunique())
このコードを実行すると、以下のように出力されます。
pclass 1 2 2 2 3 2 Name: survived, dtype: int64
この結果から、titanicデータセットにはpclassごとにsurvived列に含まれる2つのユニークな値が含まれることが分かります。
nuniqueメソッドと他のPandasメソッドの組み合わせによるデータ分析の応用例
nuniqueメソッドを使うことで、データ分析において様々な課題に対応することができます。以下の例では、titanicデータセットから性別ごとの生存率を求め、棒グラフで可視化しています。
import pandas as pd
import matplotlib.pyplot as plt
# titanicデータセットの読み込み
df = pd.read_csv('https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv')
# 性別ごとの生存率を求める
gender_survival_rate = df.groupby('Sex')['Survived'].mean()
# 棒グラフで可視化する
fig, ax = plt.subplots()
ax.bar(gender_survival_rate.index, gender_survival_rate)
ax.set_ylabel('Survival Rate')
ax.set_title('Survival Rate by Gender')
plt.show()
このコードを実行すると、以下のような棒グラフが表示されます。
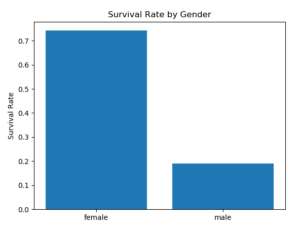
このグラフから、女性の生存率が男性の生存率よりも高いことが分かります。
まとめ
今回は、Pandasのnuniqueメソッドを使ってdistinct count(重複を除いた要素の数)を簡単にカウントする方法について紹介しました。nuniqueメソッドは、データ分析において非常に便利なメソッドであり、様々な課題に対応することができます。ぜひ、実際のデータ分析で活用してみてください。





